AGIとは
AGIは正式にはArtificial General Intelligence、つまり汎用的なAIです。完全なAGIはまだ存在せず、実現にはしばらく時間がかかると目されていますが、生成AIはAGIの一部の特徴を備えています。今後、よりAGIに近づくことは間違いないかと思われます。AGIは同時に大規模なAIで、AGIの世界では、ChatGPTに代表されるような全知全能のAIを目指しています。
新聞などを読んでいると、「パラメーターが大きい」といった言葉を目にすることがあると思います。今のコンピューターサイエンスでは、パラメーターが大きい方が良いAIだという流れがあります。大きなAIを作るためには、膨大な計算資源が必要で、GPUをたくさん購入できる人が有利になる、というゲームのような状況になっています。
代表的な企業としては、OpenAI、Google、マイクロソフトが挙げられます。Metaも頑張っていますね。そして、日本のソフトバンクですが、ソフトバンクの孫さんは先ほどの図で言うと、右側のGoogleの路線を狙っていて、半導体を作り、マシンを作り、ソフトウェアも自分で開発して、すべてを自社でまかなうという戦略を掲げています。

パラメーターとは
ここで、「パラメーター数」とは何かについて少し説明してみたいと思います。
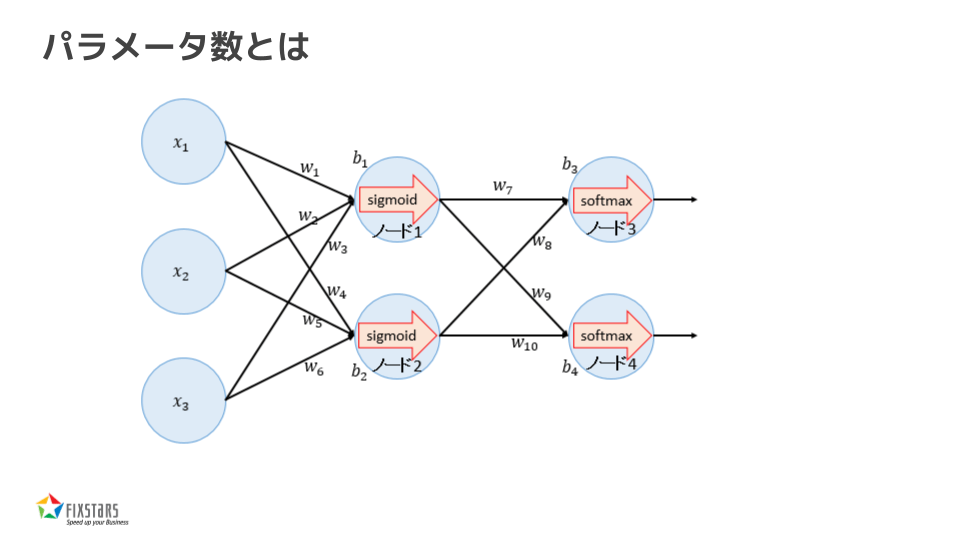
パラメーターとは、AIが学習や予測を行う際に使う「掛け算」と「足し算」に使われる数値のことです。
脳のシナプスのような写真を見たことがあるかもしれませんが、AIの構造は、脳のシナプスのように、点(丸)と線が繋がったネットワークで成り立っています。それぞれの丸の中で、受け取った数値に対して掛け算や足し算が行われ、その結果が次の丸に伝わります。
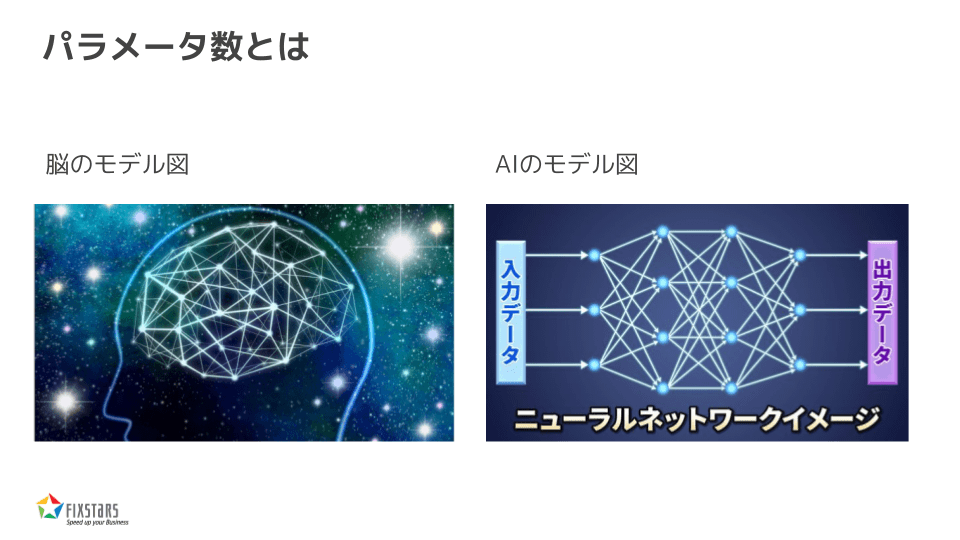
このプロセスを繰り返すことで、何と不思議、答えが出るという仕組みです。
この丸の中で行われる「掛け算」と「足し算」に使われる数値がパラメーターです。掛ける数が1つのパラメーター、足す数がもう1つのパラメーターであり、基本的に各丸の中で計算が行われると考えてください。
例えば、今主流の7000億パラメーターを持つAIでは、それらを使って丸の中で掛け算と足し算を行っています。ざっくり言うと、そんな仕組みで、AIは言葉を話せるようになっているのです。
OpenAI
OpenAIについてお話します。おそらく、多くの人々がAIに目を向けるきっかけとなったのが、GPTシリーズなのではないでしょうか。2018年に最初のモデルGPT-1が発表され、以降、毎年新しいバージョンが発表されてきました。そして、2022年11月にGPT-3.5をベースにしたChatGPTがリリースされました。
このGPT-3.5ベースのChatGPTは、人類が期待していたそれまでのAIと比較して遥かに優れており、多くの方がここからAIを使い始めたのではないかと思います。その半年後にはGPT-4が登場し、さらに1年後にはGPT-4.0がリリースされ、AIの進化が驚くべきスピードで進んでいる状況です。
Googleもこの競争に負けじと取り組んできました。現在のLLM(大規模言語モデル)の基礎技術は「Transformer」というのですが、これは実はもともとGoogleが研究して開発したものです。Googleはこの分野でリードしているつもりでしたが、OpenAIが急速に進歩したせいで、社内で緊急事態が宣言されたというニュースも出ていました。以来、GoogleはAIに多くのリソースを投入し、現在はGeminiというプロジェクトに取り組んでいます。
Googleの強みは検索エンジンの存在です。AIが裏で動くことで、検索エンジンの精度が向上しますし、Googleはすでにマネタイズの仕組みを持っているので、ビジネス面ではOpenAIよりも強いと僕は考えています。しかし、GeminiとChatGPT系の競争はまだまだ続き、性能もどんどん向上していくでしょう。
Googleはまた、NVIDIAのGPUを購入する必要がないという点でも有利です。独自のハードウェアを持っているため、NVIDIAを購入するよりも低コストでこの競争に参入できているのです。ソフトバンクも、もしかしたらこのやり方を真似したいのかもしれません。
Meta
次に、Meta(Facebook)についてです。Metaは少し出遅れたため、ユーザーの獲得のためにオープンソース化しているのではないかと思っています。Metaは最近、最新のNVIDIA H100 GPUを34万個購入したという話があります*1。先ほど述べたように、1台8000万円のGPUには8枚のGPUが搭載されており、1枚あたり500万円から600万円です。34万個購入すると、それだけで約1兆7000億円になります。これはGPUだけのコストで、実際にはコンピューターの筐体やその他の設備も必要ですので、おそらく総額で2兆円から3兆円に達するでしょう。そのような巨額の資金を投入してAIモデルを作り、無料で公開しているのです。
現在のライセンスでは、Llama 3は7億人まで無料で使用できるため、日本の全人口が利用しても無料です。私たちがLlama系のAIを使う限り、Metaが何兆円もかけて作ったものを無料で利用できるという時代です。
Llama 3のパラメーター数について言えば、現在公開されているのは700億(70B)パラメーターのモデルです。私たちの社内でも主にこの70Bのモデルを使っていますが、さらに大規模な400B、つまり4000億パラメーターのモデルも開発中で、近々リリースされる予定です*2。
ザッカーバーグ、大量のGPUを確保…2024年中にエヌビディアの「H100」を34万個
Swallow
次にSwallowプロジェクトについてです。これは東京工業大学と産業技術総合研究所が取り組んでおり、国の資金で進められています。現在、AIの学習に使われるデータの約9割が英語で、残りの1割が他言語なので日本語はほんのわずかしか含まれていません。この不足を補うために、国の資金で日本語のデータを追加学習させ、日本語対応を強化しています。先日、このSwallowプロジェクトで日本語化されたLlama 3の70Bモデルがリリースされました。
先日の新聞には、KDDIがElizaという会社に投資したという記事も出ていましたが*3、基本的には同じことをやっており、Llama 3を日本語化して商用利用向けに公開するということです。一方は国の資金で無償提供され、もう一方はKDDIが資金を投入して、おそらく有償提供されていると考えられます。
Apple
アップルもAIの分野で頑張っています。AIモデルとしては8つを公開しており、アップルの半導体「Mシリーズ」も進化しています。現在はM3が主流ですが、M4が発表され、PCではなくiPadに最初に搭載されました。今Galaxyを持っている方は、自動翻訳機能が手元で動作しているかと思いますが、こうしたエッジ側のデバイス、PCやタブレット、携帯電話でAIが活発に動く日が、もう目の前に来ていると感じます。
AGIまとめ
AGIについてまとめると、兆円単位の投資が必要なため、日本のベンチャーや大企業がこのAGIの開発競争に参加するのは難しいでしょう。1兆円を持っていても勝てない時代です。このAGIを利用するには、2つの方法があります。
1つは、ChatGPTやMicrosoftのCopilotのようにAIにリクエストして答えを得るという方法があります。これには無料のものと有料のものがありますが、ビジネスでの利用には有料のものが多く、使えば使うほどコストが上がる仕組みです。
また、データが外部に流れるリスクがあり、どれほど安全と言われていても、基本的にデータが外部に流出する可能性は否定できません。独自のAIを開発するのは難しく、データのセキュリティも問題になります。さらに、デジタル貿易赤字が増えることで、日本の富が失われることを、僕個人はとても懸念しています。
2つ目は、Metaが作っている無料のAIモデルや、さまざまなオープンなモデルを活用することがあります。これらのモデルは、ダウンロードして自分のパソコンやサーバーで利用することができます。つまり、無料のAIをさまざまな方法で活用できる時代になってきています。
この方法の特徴は、守られた自社のサーバー内で利用できる点です。自社のサーバー内で独自のデータを使い、データを外部に流すことなくカスタマイズを続けることができます。また、Metaが1兆円以上かけて開発したモデルを利用できるため、そのモデルを活用したり、他のAIモデルと組み合わせて使うことも可能です。さまざまな形でAIを活用できる時代が到来しています。
- *1ザッカーバーグ、大量のGPUを確保…2024年中にエヌビディアの「H100」を34万個

- *2405Bのパラメータを持つLlama 3.1が2024年7月23日にリリースされましたIntroducing Llama 3.1: Our
most capable models to date
- *3KDDI、生成AI開発のイライザを子会社化 DXで連携 - 日本経済新聞