AIをビジネスにどう活かすか講座
AI開発の方向性
次に、フィックスターズ、ソリューション第一事業部エグゼクティブエンジニアの二木から、AI開発の方向性と題して、自社AI開発を行う方法についてお話をしました。
LLMの利用方法について
LLMとは「大規模言語モデル(Large Language Model)」の略で、ChatGPTやGemini、Llama 3、Swallowなどのモデルの総称です。LLMの利用方法には主に以下の2通りがあります。
まず一つ目は、APIを介してLLMをホスティングしているサーバーから結果を得る方法です。もう一つは、LLMのモデルを動かすためのGPUサーバーを自社で用意して、そのサーバー上で処理を行う方法です。

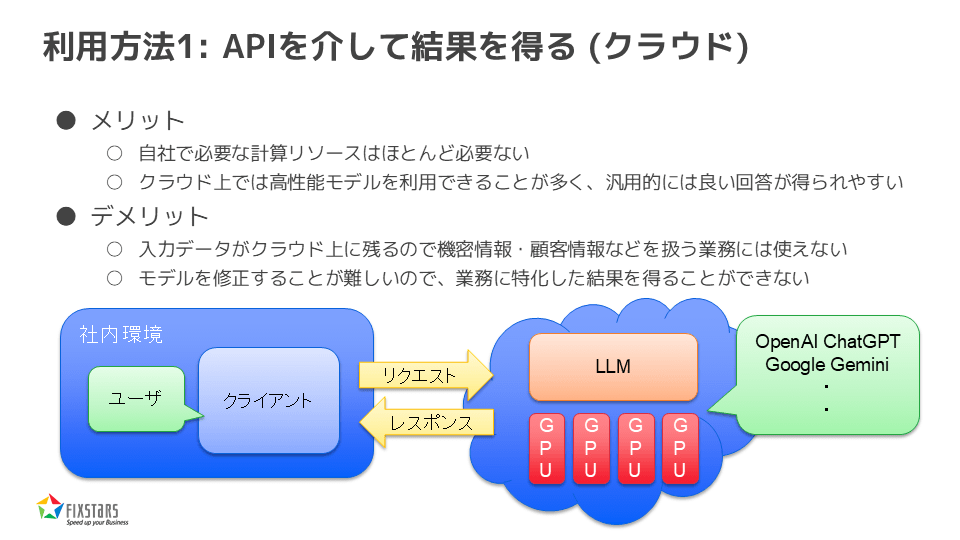
利用方法1:APIを介して結果を得る(クラウド)
まず、1つ目の方法について説明します。これは、いわゆるクラウドでの利用で、APIを通じて結果を得るというものです。
この方法にはメリットとデメリットがあり、メリットとしては、自社で必要な計算リソースがほとんど必要ないこと、そしてクラウド上では高精度なモデルを利用できることが多いため、汎用的に良い回答が得られやすいことが挙げられます。一方で、デメリットとしては、入力データがクラウド上に残るため、機密情報や顧客情報などを扱う業務には適さないことがあります。また、モデルの修正が難しいため、業務に特化した結果を得るのが難しいという欠点もあります。
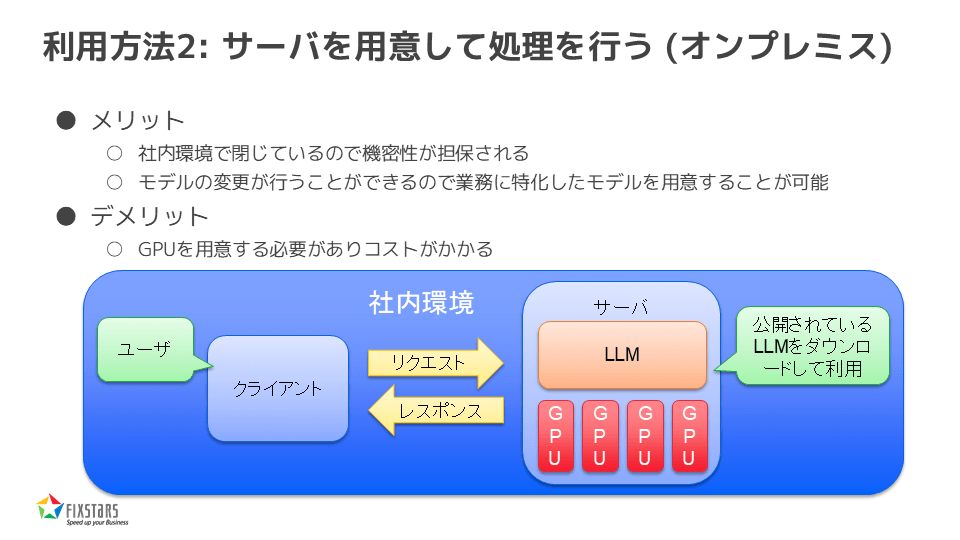
利用方法2:サーバーを用意して処理を行う(オンプレミス)
次に、2つ目の方法、オンプレミスでの利用について説明します。こちらは、GPUサーバーを用意して社内で処理を行うという方法です。この方法にもメリットとデメリットがあり、メリットとしては、社内環境で閉じているため機密性が担保されること、また、モデルの変更が可能であり、業務に特化したモデルを作成できることが挙げられます。一方で、デメリットとしては、GPUを用意する必要があり、コストがかかることが最大の課題となります。
このように、社内環境で全てを管理できることが大きなメリットとなっています。
公開されているLLMを利用する
では、どうやってそのLLMを用意するかという点ですが、これは公開されているモデルを利用することができます。自分でゼロから作成せずに、すでに公開されているものを活用するという方法です。先ほど三木からも話がありましたが、Hugging Faceというプラットフォームには多くのモデルが登録されており、それを利用できます。これは、先月までは70万モデルでしたが、今月では81万モデルに増えており*1、日々大量に登録されています。
これらのモデルの中には、日本語対応や商用利用可能なものも多数存在していますので、それを利用することが可能です。この図でも示していますように、Hugging Face Hubから好きなモデルを選んで使用できます。80万以上のモデルがあるので、どれを選べば良いのかと思われるかもしれませんが、検索機能を使って、自分の目的に合ったモデルを見つけることができます。
LLMにおける課題:ハルシネーション
次に、LLMを利用する際の課題についてお話しします。一つ目は「ハルシネーション(幻覚)」と呼ばれる問題です。簡単に言えば、LLMが嘘をつくことです。例えば、「株式会社フィックスターズは何の会社ですか?」と質問すると、ChatGPTは一見正しいような答えを返しますが、よく見ると間違った情報が混じっています。一方で、「株式会社レトリバは何の会社ですか?」と質問した場合、全くのでたらめな回答が返ってくることもあります。このように、LLMがもっともらしく誤った情報を返すことがあり、これがハルシネーションと呼ばれる問題です。

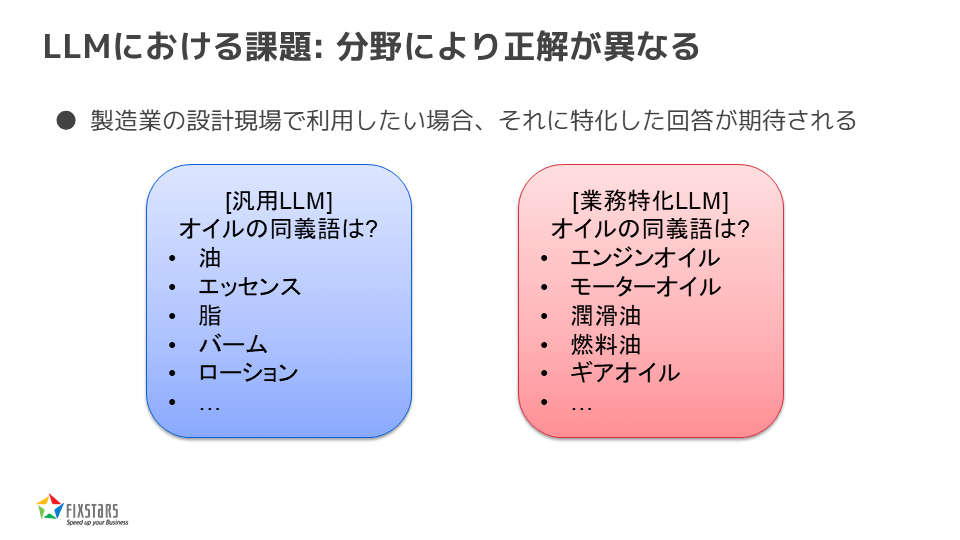
LLMにおける課題:分野により正解が異なる
もう一つの課題は、分野によって正解が異なることです。例えば、製造業の設計現場でLLMを利用する場合、その業界に特化した正確な回答が求められます。しかし、汎用のLLMでは、「オイルの同義語は?」と聞くと、一般的には「油」「エッセンス」「脂」「パーム」「ローション」などと答えるかもしれませんが、製造業の現場では「エンジンオイル」「モーターオイル」「潤滑油」「燃料油」「ギアオイル」といった回答が期待されます。これを実現するには、その分野に特化したLLMを用意する必要があります。
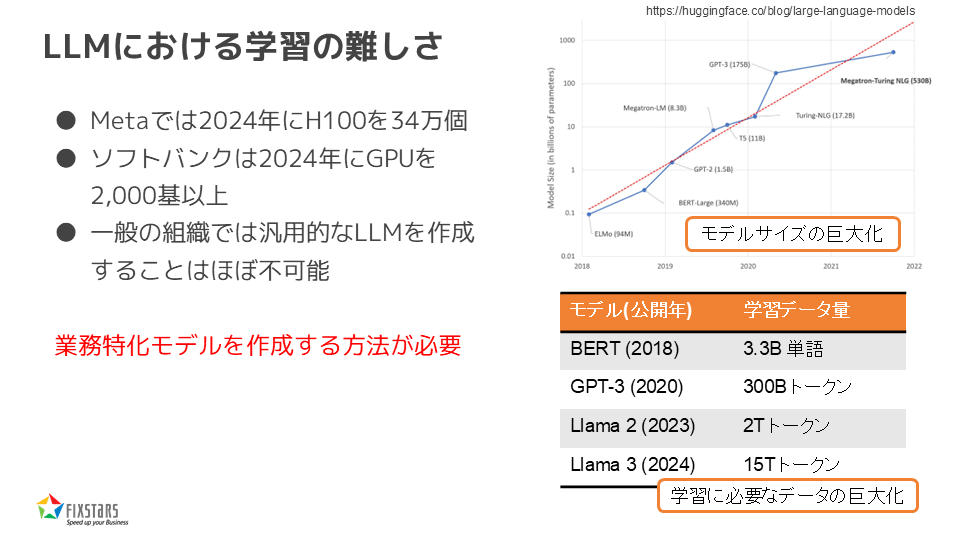
LLMにおける学習の難しさ
次に、LLMを1から用意して学習させるという選択肢についてお話ししますが、これが非常に難しいという現実があります。例えば、Metaでは2024年にNVIDIAのH100 GPUを34万個用意してLLMを作成しています。また、ソフトバンクでも2024年に2000基以上のGPUを購入*2してLLMを学習させています。このように、一般の組織が汎用的なLLMを作成するのはほぼ不可能です。
そのため、業務に特化したモデルを作成する必要が出てきます。モデルのサイズや学習に必要なデータも年々巨大化しており、2018年には33億トークンで学習していたモデルが、最新のLlama 3では15兆トークンを使って学習されています*3。これだけ大きなデータを使って学習するのは非常に難しい作業です。
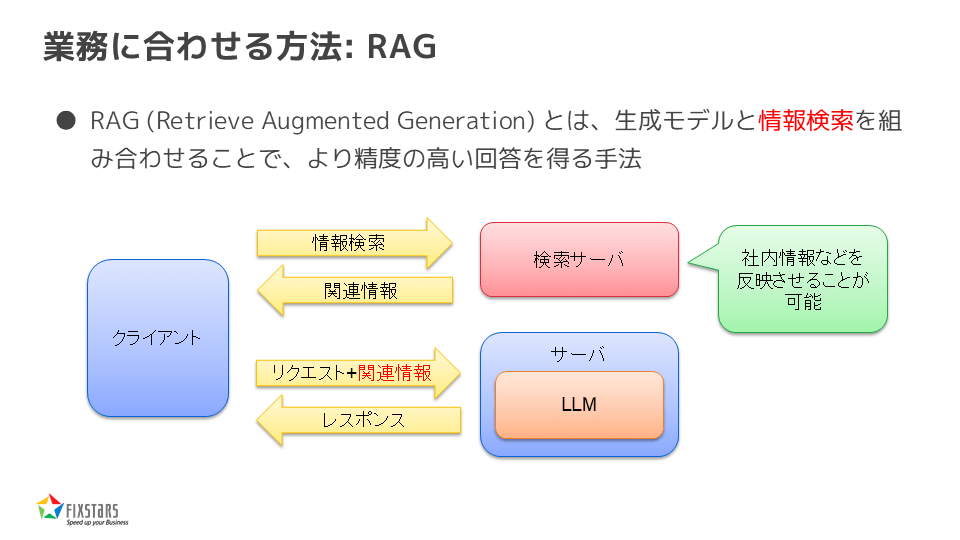
業務に合わせる方法:RAG
業務特化モデルを作成する方法として、まずRAG(Retrieval-Augmented Generation)という方法があります。これは、生成モデルと情報検索を組み合わせることで、より精度の高い回答を得る方法です。具体的には、検索サーバーを用意して社内情報を反映させ、その情報をLLMに問い合わせることで業務に合わせた回答を得ることができます。
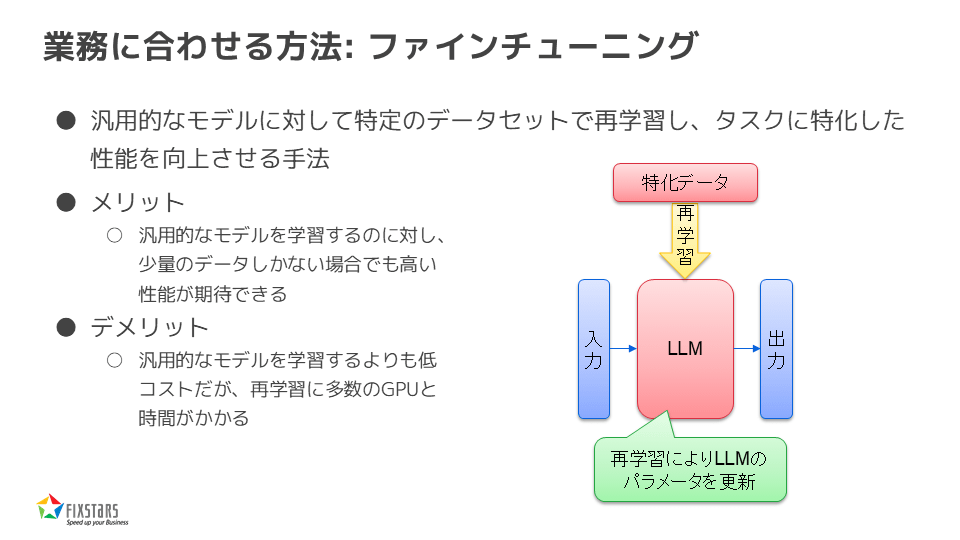
業務に合わせる方法:ファインチューニング
もう一つの方法はファインチューニングです。汎用モデルに対して特定のデータセットで再学習させることで、特定のタスクに特化した性能を向上させることができます。この方法には、少量のデータでも高い性能が期待できるというメリットがありますが、再学習にはある程度のGPUと時間が必要です。
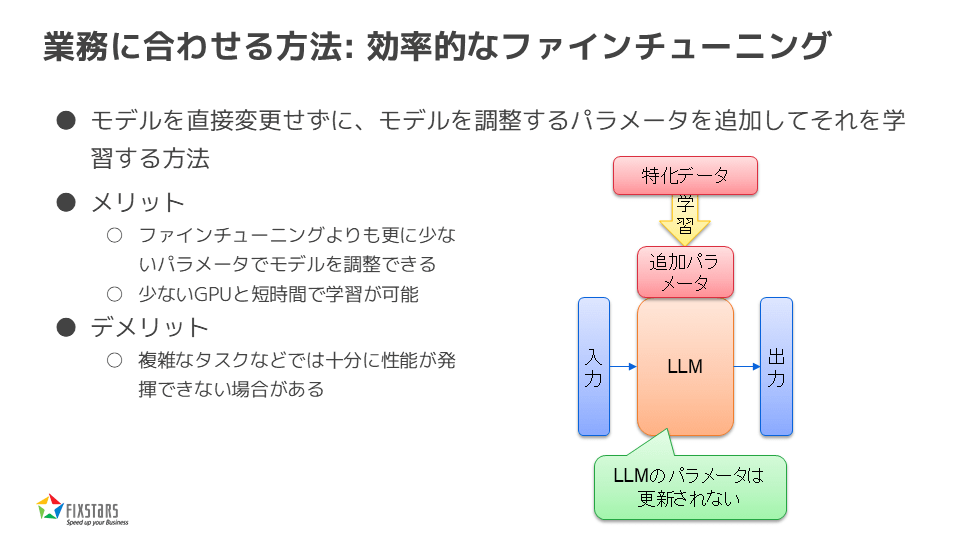
業務に合わせる方法:効率的なファインチューニング
さらに、効率的なファインチューニングとして、モデルを直接変更せずに追加のパラメーターを学習させる方法もあります。この方法では、少ないリソースでモデルを調整でき、少ないGPUと短時間で学習が可能です。ただし、複雑なタスクでは十分な性能が発揮できない場合があります。
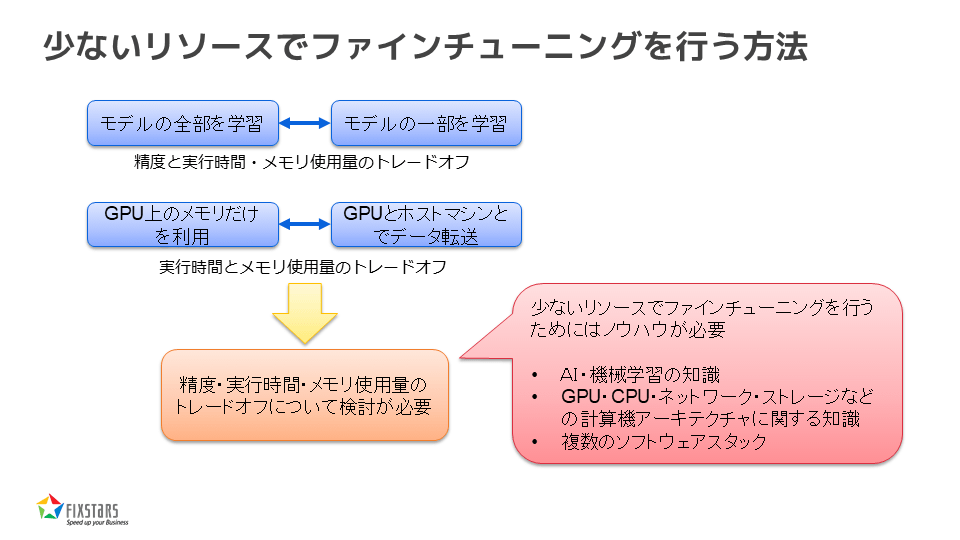
少ないリソースでファインチューニングを行う方法
以上のように、少ないリソースでファインチューニングを行うには、AIや機械学習の知識、計算機アーキテクチャに関する知識が必要です。また、複数のソフトウェアスタックを組み合わせて効率的に利用することも求められます。
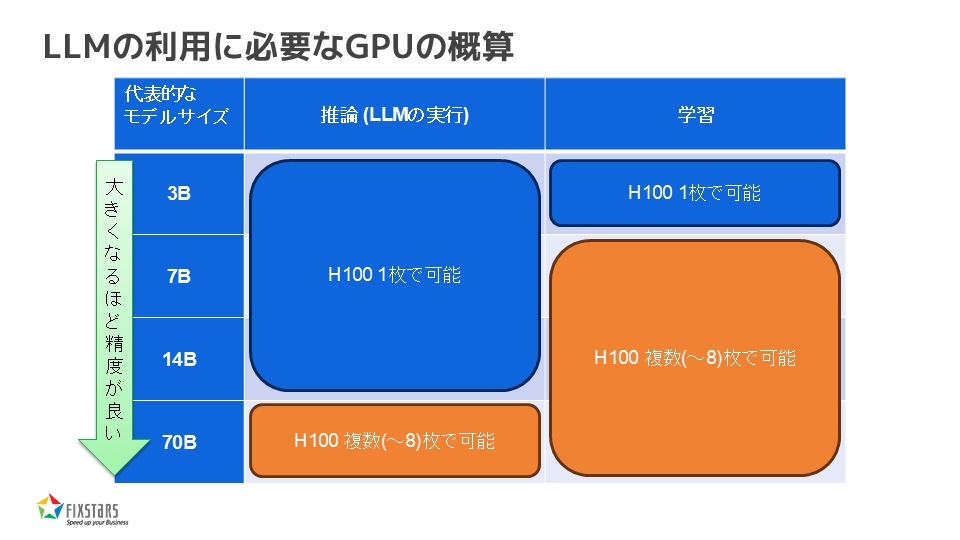
LLMの利用に必要なGPUの概算
最後に、LLMの利用に必要なGPUの概算についてお話しします。例えば、3Billion、7Billion、14Billion、70Billionといったモデルサイズに応じて、推論や学習に必要なGPUの枚数が異なります。14Billionまでであれば、NVIDIA H100 GPU1枚で推論が可能ですが、70Billion以上になると複数枚のGPUが必要です。学習においても、3BillionまでであればH100 GPU1枚で対応可能ですが、7Billion以上になると複数枚のGPUが必要になります。
以上が、LLMの利用に関する説明と、開発の方向性についての話となります。
AIをビジネスにどう活かすか講座
- 1 AIの最新動向
- 2 AGIについて
- 3 Domain Specific AI
- 4 AI活用事例
- 5 AI開発の方向性
- 6 AI開発のススメ