
Maximize Hardware Efficiency, Minimize Operational Costs.
Fixstars AI Booster optimizes hardware resource utilization and accelerates both training and inference processes, enabling cost-efficient AI development and operations. It supports a wide range of hardware environments and scales effortlessly from a single node to large-scale clusters.
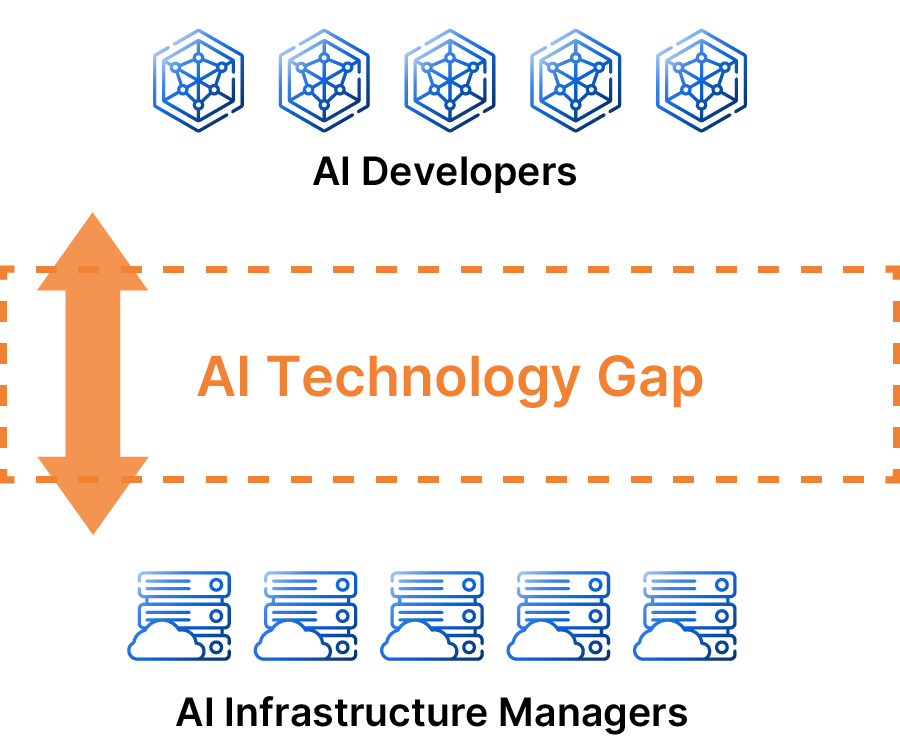
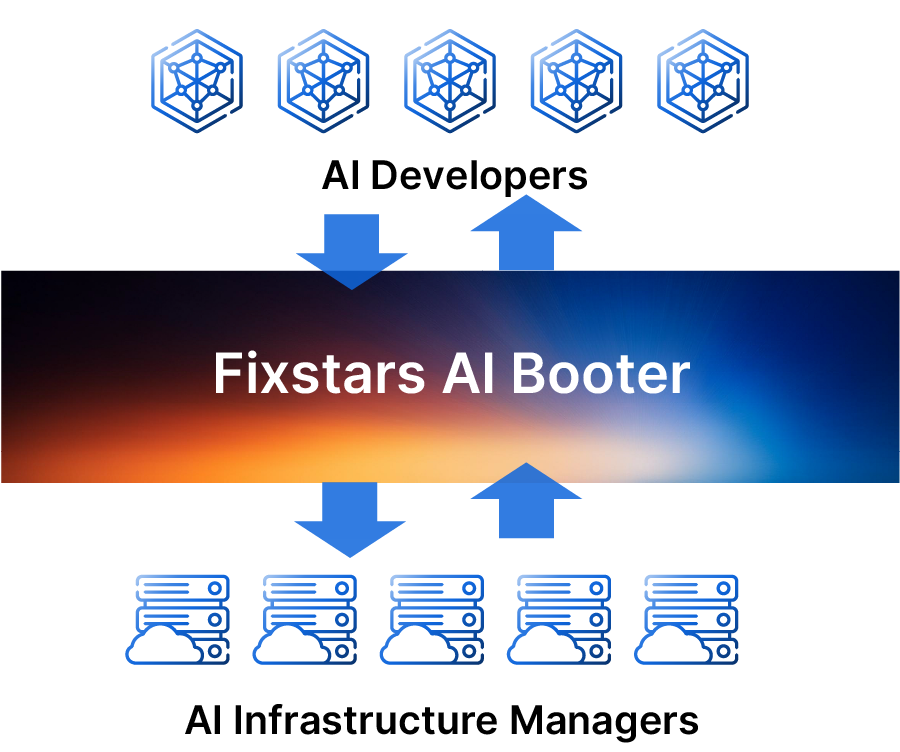
Bridging the AI Technology Gap with
General-purpose GPU cloud services only provide hardware, requiring companies to build their environment and verify operation before starting development.
Fixstars AI Booster includes middleware and an integrated development system for AI model development, significantly reducing setup effort and time.
With very high-performance GPU-equipped servers, using them in a standard way may not fully utilize their performance.
Fixstars AI Booster, as an "AI Acceleration Platform," maximizes GPU performance and accelerates processing.
What is AI Acceleration Platform?
 This high-end GPU should cut processing time in half!
This high-end GPU should cut processing time in half!
 It's only about 20% faster...
It's only about 20% faster...

Why processing time may not be reduced as expected?




By increasing processing speed and cutting down training time, Fixstars AI Booster significantly reduces the cost per training run.
| Cloud A | Cloud B | Cloud A +Fixstars AI Booster |
Cloud B +Fixstars AI Booster |
|
|---|---|---|---|---|
| Node usage fee | $71,773 (On-demand) |
$20,000 (Monthly) |
$71,773 (On-demand) |
$20,000 (Monthly) |
| Processing performance | 1(Standard) | 1 | x2.5 | x2.5 |
| Usage period | 6 month | 6 month | 6 month | 6 month |
| Setup Period | 1 month | 1 month | - | - |
| Number of training runs possible within the period | 2.0 | 2.0 | 5.9 | 5.9 |
| Days per training run | 76 days | 76 days | 30 days | 30 days |
| Cost per training run | $435,867 | $121,533 | $145,267 | $40,533 |
In fields demanding advanced computation and large-scale data processing, it fully harnesses GPU performance to significantly enhance development efficiency and productivity.

We will accelerate your AI models and fine-tune Fixstars AI Booster to match your specific development environment and requirements.

We offer GPU server recommendations and setup support tailored to your needs and development environment.

We can propose various cloud services or on-premises servers equipped with NVIDIA’s high-end GPUs.
Modification is not needed. Built on standard open-source middleware used in generative AI/LLMs, it typically works with common code. For further performance improvement, adding arguments may be recommended.
Most likely. Our middleware integrated features realizing high efficiency based on the latest research papers. However, the speedup factor depends on your applications. Please consider our GPU workload analysis service for more details.
We optimized LLM middleware to the target servers. For instance, we tuned multi-GPU/multi-node communication and file storage for our cloud environment, resulting in 2.1x-3.7x performance boots.
Fixstars engineers acquired knowledge and skills to accelerate a large variety of computations including AI/ML from our engineering services. So we can apply acceleration techniques we have cultivated so far to this field.