
There's been considerable excitement surrounding Large Language Models, and the remarkable opportunities they present. In this article, I'll explore the step-by-step procedure of crafting a chatbot for either personal use or company team on Slack. This intelligent assistant will have the capability to provide answers based on the multiple documents provided. Most importantly, everything is running on the on-premise, we can easily manage and maintain the system without relying on any cloud service such as openAI.
Before we continue, there are some key concepts I would like to clarify:
- Large Language Model: An AI model that is designed to process and understand human language. It uses a vast amount of data and computational power to learn patterns, structures, and relationships within language, enabling it to perform various natural language processing (NLP) tasks.
- Semantic Search: Semantic search is a search technique that aims to understand the meaning behind user queries and the context of the content available on the web. Unlike traditional keyword-based search, which relies on matching specific words or phrases, semantic search uses artificial intelligence and natural language processing to comprehend the intent and context of the search query.
- Text Embedding: Text embedding is a way of representing words or sentences as dense vectors, capturing their semantic meaning and relationships. By representing words and documents in a meaningful way, semantic search engines can find relevant information even if the exact keywords are not present, leading to more accurate search results.
- Facebook AI Similarity Search(FAISS) Faiss is an open-source library developed by Facebook for fast similarity search and clustering of vectors. It is used to find similar items in large datasets efficiently and is commonly used in image retrieval, text search, and recommendation systems. It largely speed up semantic search process.
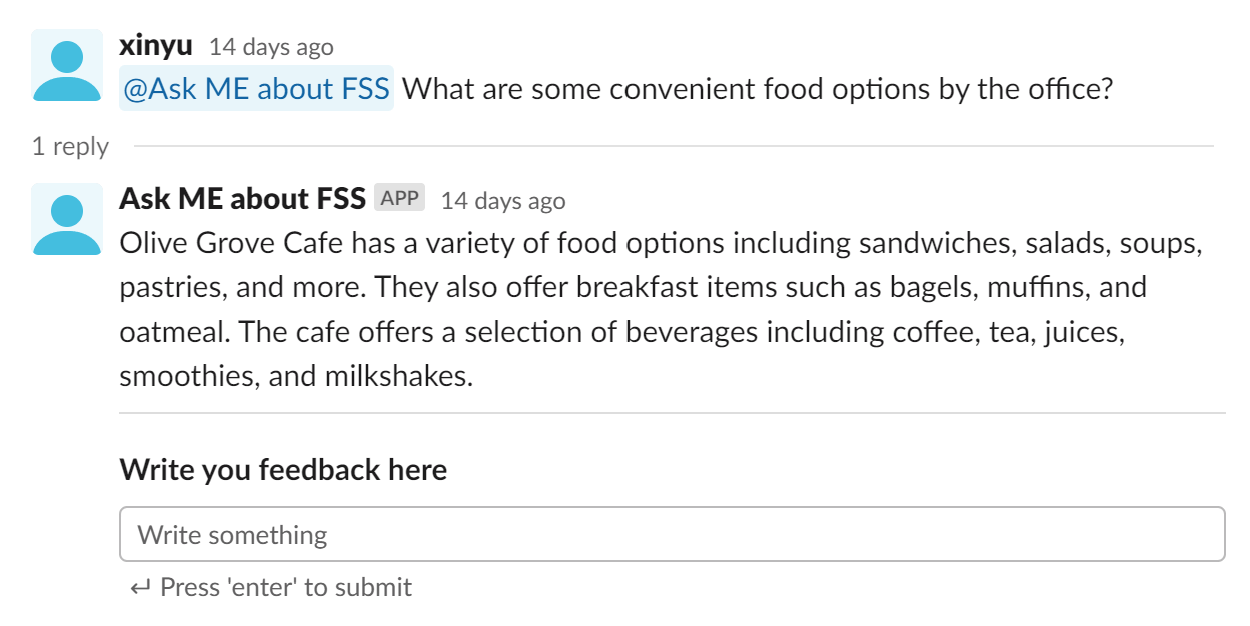
Great! With all the prior knowledge we have, we can now understand how the Slack bot functions!
How the slackbot works?
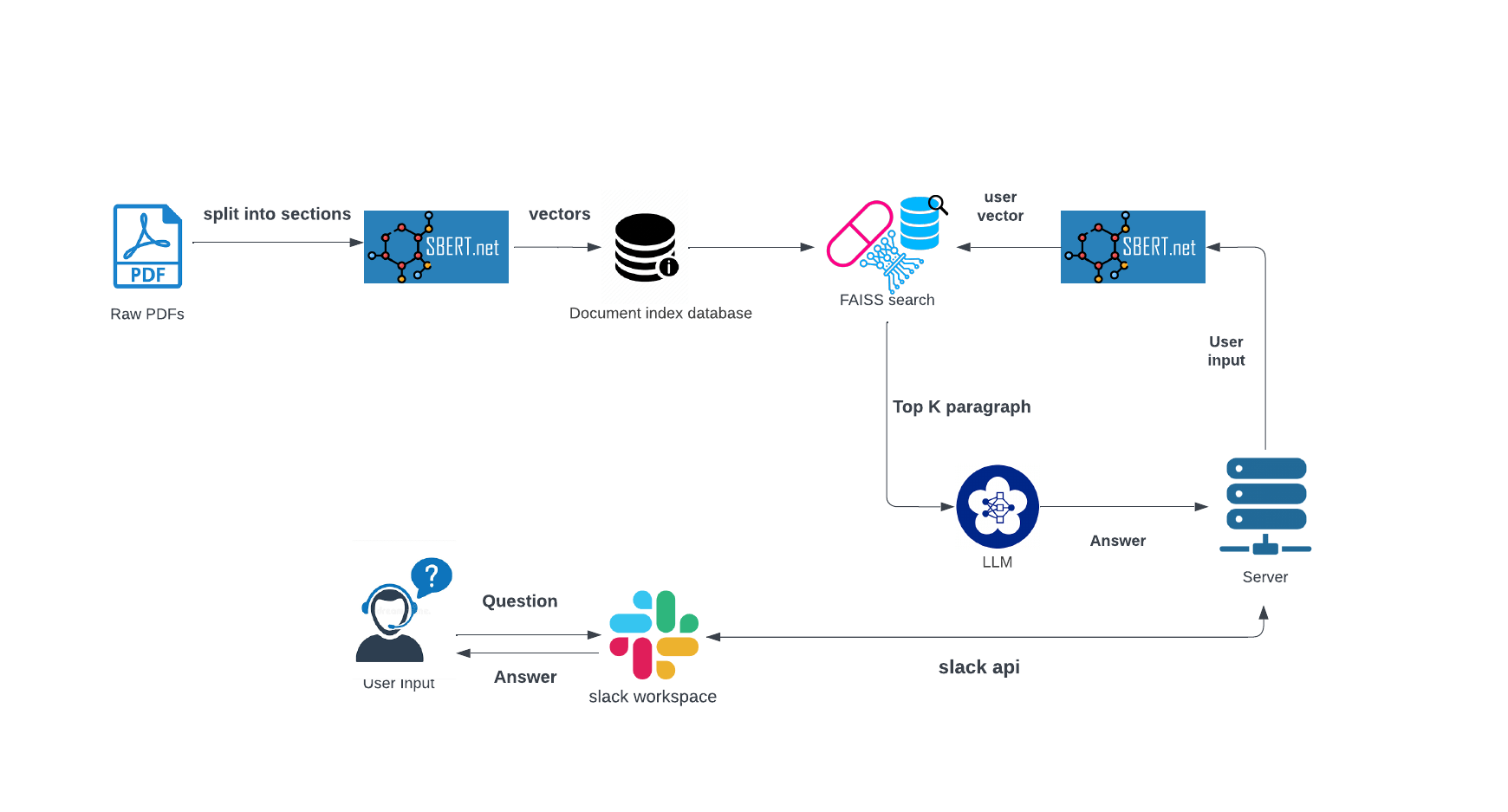
1. Prepare the knowledge base
First I split the document into chunks together with the local text embedding model
sentenceEmbedding = SentenceTransformerEmbeddings(model_name = "all-mpnet-base-v2")
to embed each text chunk, and then utilize FAISS to construct a vector database.
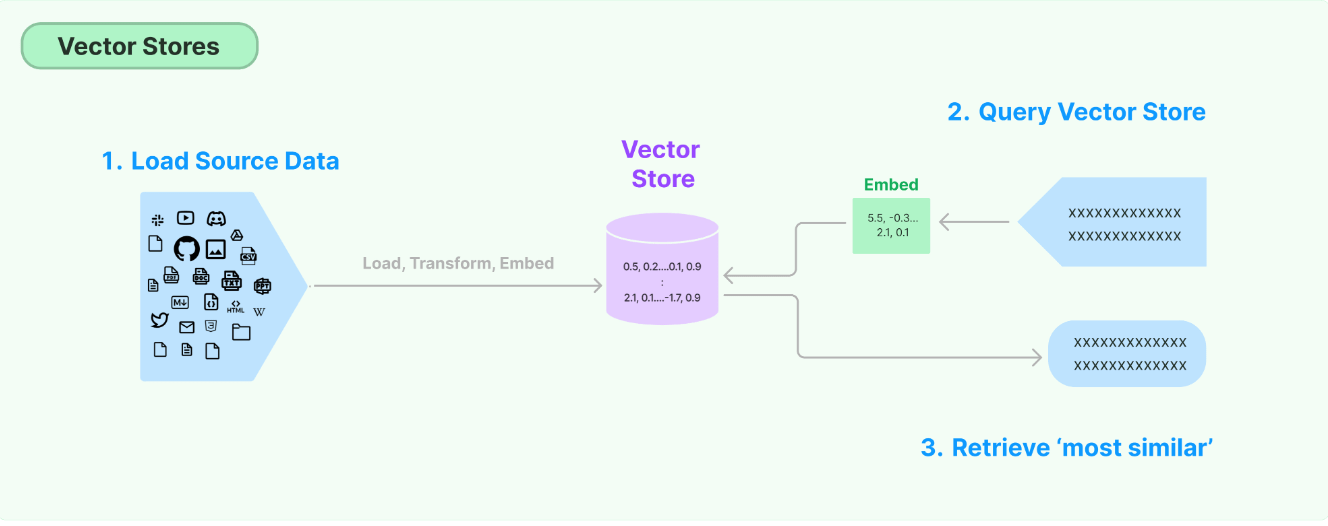
This walkthrough uses the FAISS vector database, which makes use of the Facebook AI Similarity Search (FAISS) library.
def create_vectore_store(rootdir, embeddings=sentenceEmbedding, loadfile="./faiss_index", load=True):
if load:
try:
db = FAISS.load_local(loadfile, embeddings)
return db
except:
print("no local database! Please create your own database.")
documents = []
for subdir, dirs, files in os.walk(rootdir):
for file in files:
filename = os.path.join(subdir, file)
# different dataloader according to different type of documents
if filename.lower().endswith(".mhtml"):
loader = MHTMLLoader(filename, bs_kwargs={'features': 'html.parser'})
documents.extend(loader.load())
elif filename.lower().endswith(('.png', '.jpg', '.jpeg')):
loader = ImageCaptionLoader(filename)
documents.extend(loader.load())
elif filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents.extend(loader.load())
text_splitter = TokenTextSplitter(chunk_size=SECTION_LENGTH, chunk_overlap=MAX_SECTION_OVERLAP)
docs = text_splitter.split_documents(documents)
db = FAISS.from_documents(docs, embeddings)
db.save_local(loadfile)
return db
2. Semantic search using FAISS
To use FAISS library for semantic search, we first load our vector dataset (semantic vectors from sentence transformer encoding) and construct a FAISS index. The embeddings are then stored in an index, which allows for efficient retrieval and matching of relevant information during the query process.
The core of the semantic search lies in this two Python lines:
embedding_vector = embeddings.embed_query(user_input)
docs = db.similarity_search_by_vector(embedding_vector, k=top_n)3. Retrieve the semantic search result and generate prompt
Each LLM has its own format of prompt, I start with this prompt which includes a "system message" and the user request:
An example prompt for Alpaca:
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
### Instruction:
Answer ONLY with the facts listed in the sources below.
If there isn't enough information below, reply I don't know.
Do not generate answers that don't use the sources below.
Sources:
{Smantic Search Result}
### Input:
{user_input}
### Response:4. Construct the response by LLM with prompt provided
OpenAI is brilliant but has mainly three disadvantages
- Expensive: The service comes at a high cost, which may not be feasible for every organization.
- Obscure: We are unable to further fine-tune the Azure OpenAI API, limiting customization and adaptation to specific needs.
- Unsafe: There are concerns regarding information leaks associated with the Azure OpenAI API, posing potential risks to sensitive data.
For LLM inference, I provide two options for local LLM use. It allows us to run LLMs and serves as a drop-in replacement for OpenAI service.
I evaluate our local model and openAI service with following criteria and 4 prepared questions.
The testing criteria is as follows:
- Get output (T/F): True if the system returns any answer
- Complete Sentence (T/F): True if the system output is a complete sentence grammatically.
- Correctness (T/F): True if the output provides the right answer (including numbers) as we expected
- Speed (in s): record the time elapsed between the generated answer and the user's input.
- The amount of information (1-5): 5 if the answer has complete information that we expected and not too wordy
OpenAI Service Result
| Question_id | Overall score(1-5) | Evaluation |
|---|---|---|
| 1 | 5 | accurate and fast |
| 2 | 4.85 | fast,accurate but too wordy |
| 3 | 3.6 | fail to provide information |
| 4 | 5 | accurate and fast |
Local LLM Result
| Question_id | Overall score(1-5) | Evaluation |
|---|---|---|
| 1 | 3.85 | too slow |
| 2 | 5 | fast and concise |
| 3 | 5 | correct and fast |
| 4 | 4.3 | lack information |
In this scenario, with further optimization to speed up and minimizing the model size, the local LLM exhibits great potential to excel in performing our task.
5. Intergrate to slack channel
A bot is a type of Slack App designed to interact with users via conversation. It can access the same range of APIs and do all of the magical things that a Slack App can do.
The core funcion is as follows:
@app.event("app_mention")
def handle_app_mention_events(body, say, logger):
message = body["event"]['text']
thread_ts = event.get("thread_ts", None) or event["ts"] ## chatbot reply in thread
......
# perform semantic search and generate answers
answer,content = llm.get_response(db, user_input=message)
# post answer in slack channel
say(
text=answer,
thread_ts=thread_ts,
blocks = [
{
"type": "section",
"text": {
"type": "plain_text",
"text": answer,
"emoji": True
}
},
{
<ADD ANY SECTION YOU LIKE HERE>
},
]
)OpenAI service
How to run LLM inference on limited GPU source?
One of the biggest challenges with LLMs is dealing with their large GPU memory requirements.
If loaded in full precision, it requires more than 7B * 4 = 28GB to load the model
weights and parameters
- LLM.int8() is a quantization method, which is implemented in the bitsandbytes library and helps to transfer the model into 8 bit.
- GPTQ is SOTA one-shot weight quantization method, with this novel 4-bit quantization techniques, we can run 7B LLM inference in a single 8G gpu.
What to do in the future?
- Improve image captioning and integrate into Slack bot: Enhance image description generation and text extraction for images in Slack chatbot.
- Regular database updates with user information: Keep database up to date, including user-provided information.
- Meta released their new LLama weights and further improvement can be done
Fixstars recently announced research project with SAKURA Internet for the domain-specific LLM (Press Release, only in Japanese). We will accelerate our activities by using LLM and related technology as we mentioned in this article.
Reference
- Stanford Alpaca: A Strong, Replicable Instruction-Following Model Rohan Taori*, Ishaan Gulrajani*, Tianyi Zhang*, Yann Dubois*, Xuechen Li*, Carlos Guestrin, Percy Liang, Tatsunori B Hashimoto Blog Post / Code & Data
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained TransformersElias F rantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh
- https://github.com/tloen/alpaca-lora

- https://github.com/qwopqwop200/GPTQ-for-LLaMa